Making the most of Apple Foundation Models: Routing

The evolution of models took us from text-only models that generate text, to image-only, to many more modalities, and eventually to multi-modal models. Multi-modal models can generate multiple content types at once. The advantage is that they represent text, images, and other modalities in the same latent space, which enables seamless integration and high precision when you operate on images or text, switching between modalities effortlessly.
The model that Apple ships this year is not as powerful or fully featured. To enable a similar experience, we fall back on a technique called routing.
What Routing Is
Routing takes a first very quick pass over the user message, extracts intent, and then sends the actual request to the right model or tool. On the product side we stitch the whole thing into a single experience that feels native and coherent.
How To Achieve This With Apple Frameworks
It should be evident that we will be maintaining our own messages. We cannot rely on the transcript of a single language model session because we are stitching multiple tools into one.
1. Tag the incoming user query
We detect whether the user wants to generate an image or text by configuring the system language model for the contentTagging use case. In my experimentation, I never got this to work against an enum that directly represents the request type. Instead, I created a struct with fields like actions, objects, and topics, then added simple heuristics, you can experiment with what makes most sense in your product.
@Generable
struct RoutingTags {
@Guide(description: "Most important actions in the input text.", .maximumCount(3))
var actions: [String]
@Guide(description: "Most important objects in the input text.", .maximumCount(5))
var objects: [String]
@Guide(description: "Most important topics in the input text.", .maximumCount(3))
var topics: [String]
}These heuristics work well and have been robust in testing, though they may change over time. Flow so far is take the user query, run contentTagging, and use the heuristic result to decide if this is an image request or not.
func tagMessage(_ text: String) async throws -> RoutingTags {
let model = SystemLanguageModel(useCase: .contentTagging)
let session = LanguageModelSession(model: model)
return try await session.respond(to: text, generating: RoutingTags.self).content
}And by heuristics I mean something quite unholy like this:
func isImageRequest(tags: RoutingTags, original: String) -> Bool {
let s = original.lowercased()
let keywords: Set<String> = [
"image", "picture", "photo", "photograph", "draw", "drawing", "sketch",
"illustration", "art", "logo", "icon", "wallpaper", "render"
]
func containsKeyword(_ text: String) -> Bool {
for k in keywords { if text.contains(k) { return true } }
return false
}
if containsKeyword(s) { return true }
let allTags = (tags.actions + tags.objects + tags.topics).map { $0.lowercased() }
for t in allTags {
if containsKeyword(t) { return true }
}
return false
}once again it works remarkably well, but I recognize you might want to revisit the logic here :)
2. If it is an image request
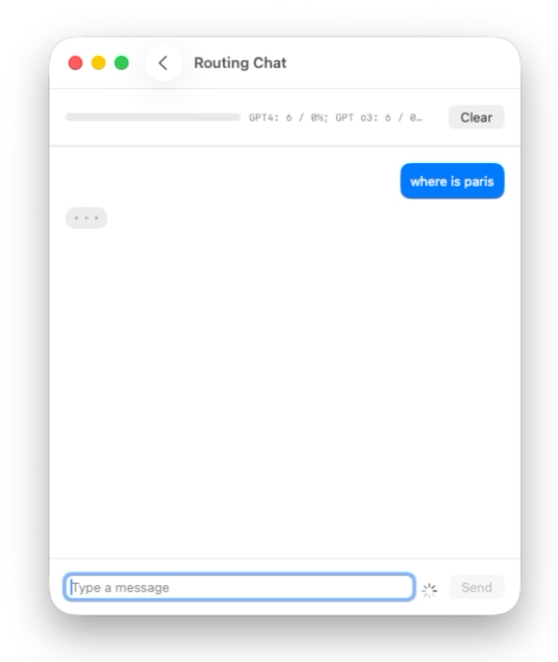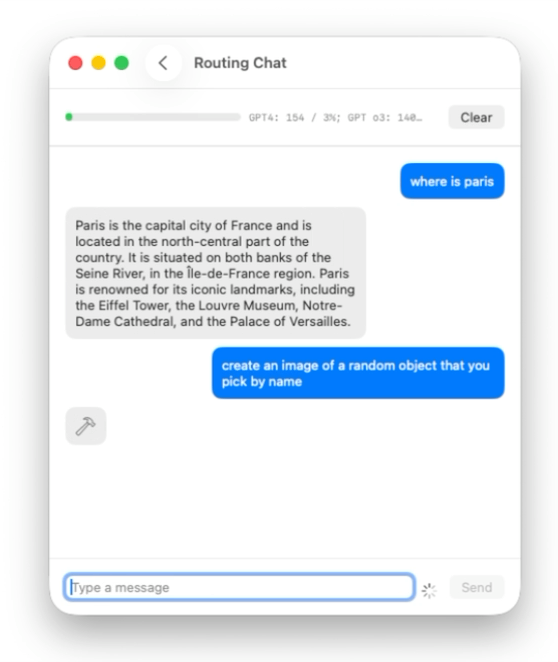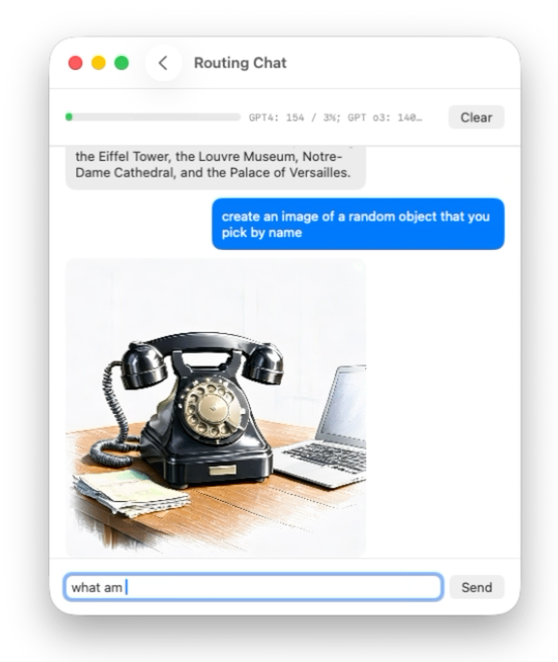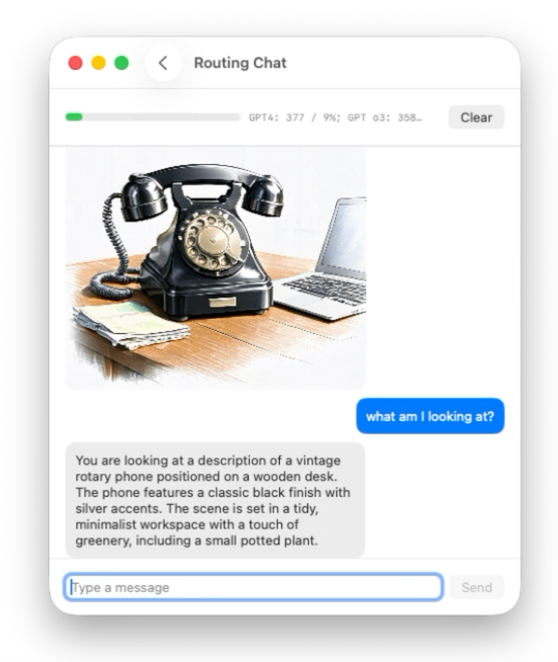
Image generation models respond better to more detailed prompts. So we start with prompt enhancing.
Prompt enhancing
Create a separate model whose only task is to take the user query that was detected as image intent and produce a richer, more detailed image description. It should also strip anything irrelevant to image generation.
let promptRewriter = LanguageModelSession(instructions: """
You are an expert image prompt engineer. Given a user request, write a concise, vivid prompt suitable for a modern image generator. Include subject, key attributes, style, composition, lighting, and mood. Avoid brand/style names or people it will fail. Output only the prompt, no extra words.
""")
let newPrompt = try await self.imagePromptEngineer.respond(to: originalPrompt).contentGenerate the image
Use Image Playground’s image creator to feed the enhanced text prompt, configure styles, and receive the image as output. Then take the expanded prompt and create a hidden message for the main LLM that says there is an image, the model cannot see it, and here is the description. This will matter in a moment.
let creator = try await ImageCreator()
let style = creator.availableStyles.randomElement()!
let sequence = creator.images(for: [.text(newPrompt)], style: style, limit: 1)
for try await created in sequence {
guard let png = self.pngData(from: created) else { continue }
// Optionally get a VisionKit to describe the image
// let visionSummary = await ImageAnalysisService.describeImage(data: png)
return ImageWithMetadata(image: png, description: "[image placeholder]\nImage description: \(newPrompt)")
}Finally we need to render it all. Stitch the result into the UI so it appears in one continuous thread.
3. If it is not an image request
Send the query to the main LLM as a regular text message, let it respond, then render that response as usual.
Keeping Image Context Alive Across Turns
Once we have images in the thread, the next time the user refers to them the language model session will not inherently know an image exists. This is why we kept the image description. We can perform a small sleight of hand and include that description so the model behaves as if the image is present. The user can continue to ask questions about the image, iterate, and issue delta requests, for example:
You ask to generate a cup, the model generates a cup. Next you ask to create the same cup but blue. The routing still identifies this as an image request and reconciles the delta against the previous step.
This adds a bit of complexity. You will often pass more than one message into the prompt enhancer for image creation so it can understand context. The tradeoff is worth it for a good user experience.
Extending Beyond Images
You can extend the same technique to audio and other media types. You can also add more advanced processing. For example, use the Vision framework to analyze the image, produce richer descriptions than the prompt enhancer alone, and supply that to the main model for better understanding.
This is it for the current installment of this series. The approach above should help create a better, more seamless user experience with Apple’s Foundation Model while adding capabilities that the base model does not provide on its own.